

MapReduce 作为处理大数据的强大工具,在数据密集型任务中发挥着重要作用,随着技术的进步和需求的增加,新的框架和工具被开发出来,以弥补 MapReduce 的不足,并在某些情况下替代它,小编将探讨这些替代技术的特点、优势以及使用场景。
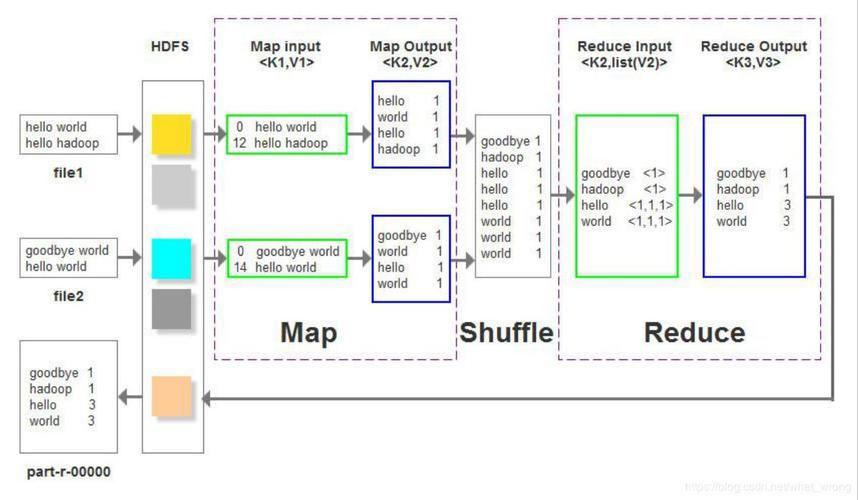
1、Hive统计部件
概念与特点:Hive是建立在Hadoop之上的数据仓库,它允许用户通过类似SQL的查询语言来进行数据分析。
优势对比:Hive的学习成本相对较低,并且可以通过SQL语句实现快速MapReduce统计,使得MapReduce操作变得更加简单快捷。
适用场景:适用于需要进行快速统计分析而不需要开发专门的MapReduce应用程序的场景。
2、Apache Spark
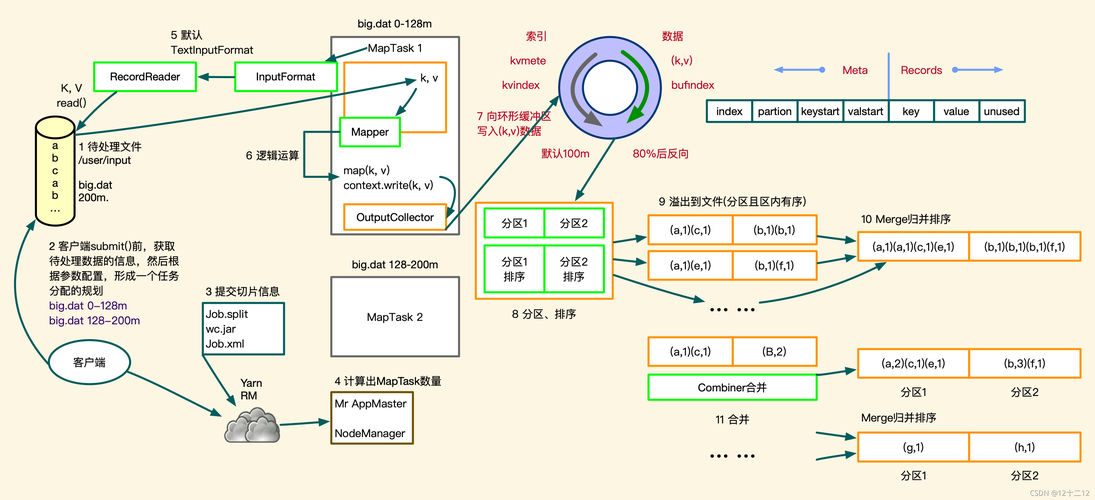
计算效率:Spark在许多情况下的计算效率比MapReduce高,特别是在进行迭代算法和实时数据处理方面。
灵活性与实时性:Spark不仅强大、灵活,而且提供了更好的实时性,这使得它成为MapReduce的一个更现代化的替代品。
广泛应用:由于上述优点,Spark已被广泛应用于机器学习、图处理等多种复杂的数据应用场景。
3、Tez优化引擎
性能提升:Tez是Hive中的一个优化引擎,能够有效减少MapReduce作业的执行时间,提高性能。
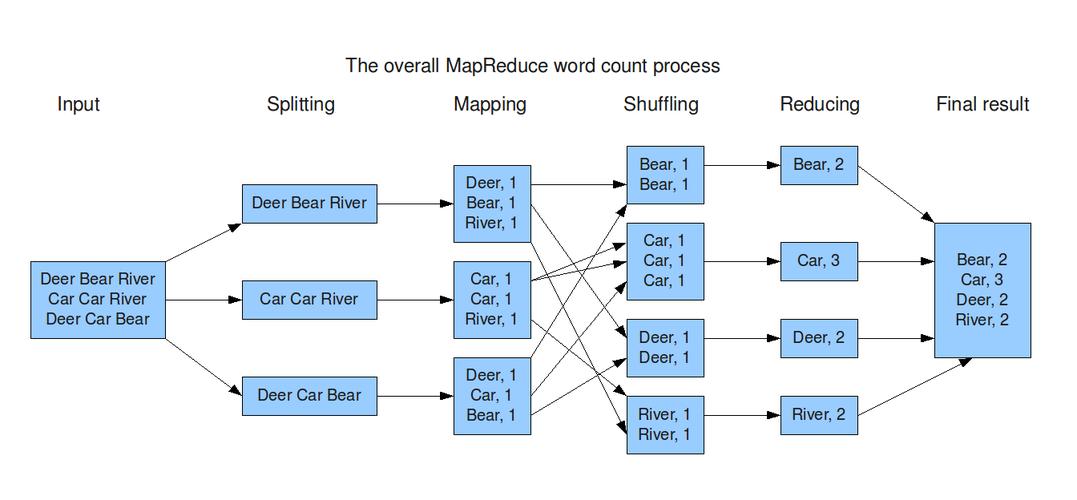
优化策略:通过优化作业间的数据传递和避免不必要的数据写入磁盘来加速数据处理过程。
应用场景:适合需要高性能Hive查询的场景,特别是在数据探索和大规模数据分析工作中。
MapReduce虽然是一个强大的大数据处理模型,但随着技术的发展,新的工具如Hive和Spark等提供了更多的优化和便利,能够满足现代数据处理的多样化需求,选择正确的工具对于提高数据处理效率和降低成本至关重要。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591624.html
 微信扫一扫
微信扫一扫 