

MapReduce历史服务(MRS)

深入理解MapReduce服务及其配置过程
1、Hadoop MapReduce服务简介:
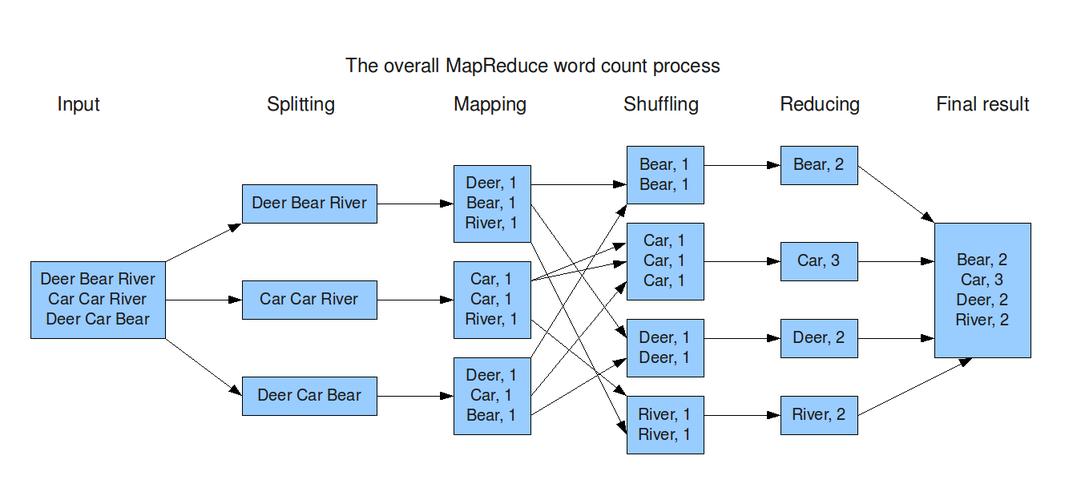
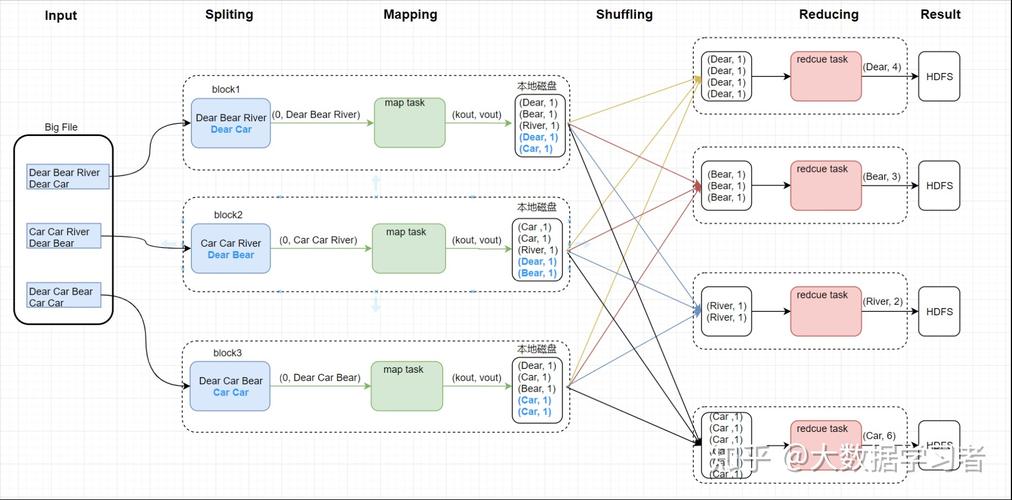
Apache Hadoop是一个开源框架,它允许使用简单的编程模型进行分布式处理,MapReduce是Hadoop的核心组件之一,它使得大规模数据集的处理变得简单和高效。
MapReduce作业通常分为两个阶段执行:Map阶段和Reduce阶段,每个阶段都由一个或多个并行任务组成,这些任务可以在不同的数据上独立运行。
2、历史服务器的作用与重要性:
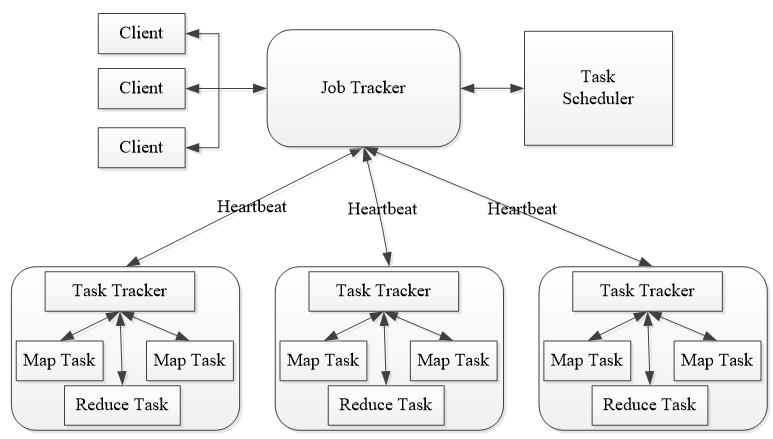
历史服务器是Hadoop生态系统中的一个组件,主要用于跟踪和记录MapReduce作业的历史信息。
通过查看历史服务器,用户可以获取关于已完成的MapReduce作业的详细日志,例如使用的Map和Reduce任务数量、作业的提交、启动和完成时间等。
3、配置历史服务器的步骤:
在配置历史服务器之前,需要确保Yarn已被正确关闭,以避免配置冲突。
编辑mapredsite.xml文件,这是配置MapReduce历史服务器的关键步骤,此文件通常位于Hadoop安装目录下的etc/hadoop/文件夹中。
4、查看和管理作业日志:
一旦历史服务器被正确配置,用户可以通过Web界面访问它来查看过去的MapReduce作业详情。
这对于调试和优化MapReduce作业非常有帮助,用户可以从中了解哪些部分执行得好,哪些部分可能需要改进。
5、常见问题及解答:
问题1: 如何确认历史服务器配置成功?
回答: 可以尝试访问默认的历史服务器URL(如http://<历史服务器地址>:19888),查看是否能显示历史作业列表。
问题2: 历史服务器是否会影响当前运行的MapReduce作业?
回答: 不会,历史服务器仅记录已经完成的作业信息,对正在运行的作业没有影响。
MapReduce历史服务(MRS)是Hadoop框架中一个非常有用的功能,它帮助用户追踪和管理MapReduce作业的历史数据,通过简单的配置步骤,即可启用历史服务器,从而获得对过去作业性能的深入了解,并据此优化未来的数据处理任务,希望以上内容能够帮助您更好地理解和利用MapReduce历史服务。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591740.html
 微信扫一扫
微信扫一扫