

MapReduce在朴素贝叶斯分类中的应用解析

| 主标题 | |
| 介绍MapReduce和朴素贝叶斯分类的结合点及应用场景 | |
| MapReduce基础 | 解释MapReduce模型的核心思想及其在数据处理中的角色 |
| 朴素贝叶斯分类 | 描述朴素贝叶斯分类的统计学原理及实现步骤 |
| 结合MapReduce实现朴素贝叶斯分类 | 阐述如何使用MapReduce框架进行朴素贝叶斯分类的训练和预测过程 |
| 案例分析 | 通过一个具体例子说明MapReduce在朴素贝叶斯分类中的应用 |
| 相关问题与解答 | 提出并解答两个与主题相关的问题 |
1、
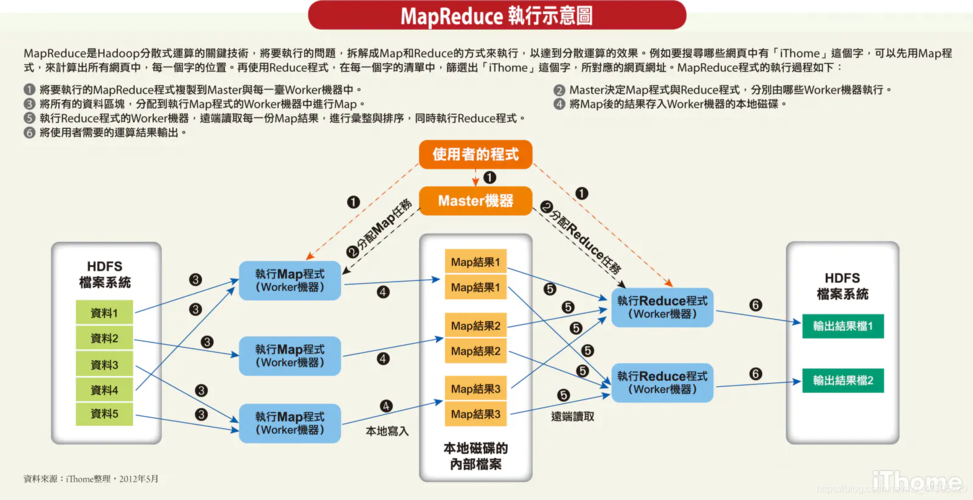
MapReduce作为一种强大的分布式计算模型,其在处理大规模数据集时表现出了显著的优势,朴素贝叶斯分类器,作为基于概率统计的分类方法,在文本分类、垃圾邮件检测等领域有着广泛的应用,将MapReduce与朴素贝叶斯分类相结合,不仅能够提高分类任务的处理效率,还能在保证分类质量的同时处理更大规模的数据集。
2、MapReduce基础
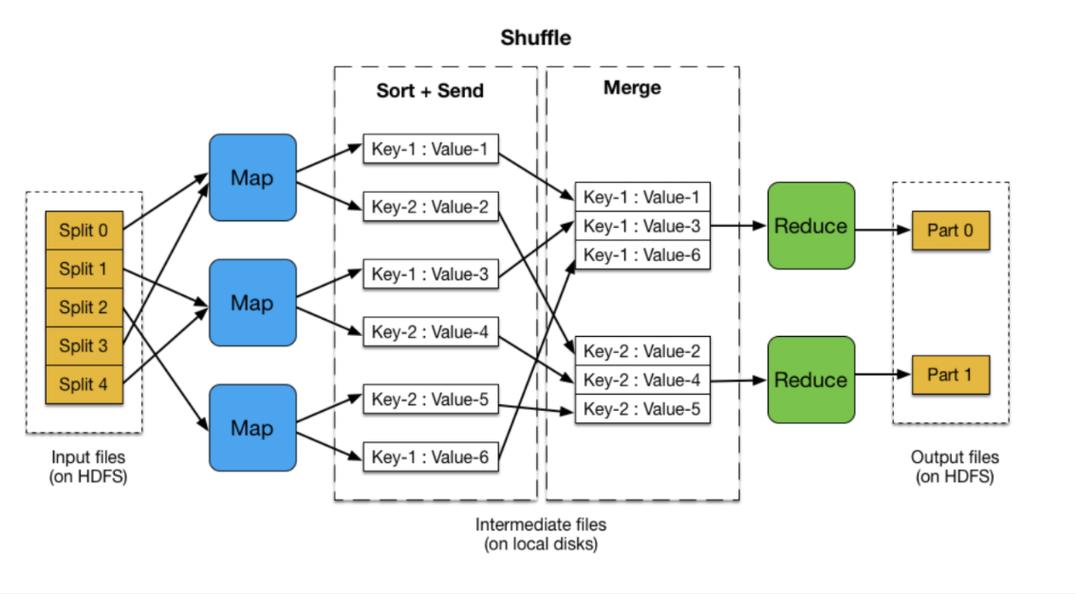
MapReduce编程模型主要包括两个阶段:Map阶段和Reduce阶段,在Map阶段,程序通过用户定义的Mapper函数,接受输入数据并产生一组中间键值对;而在Reduce阶段,通过用户定义的Reducer函数,这些中间键值对被处理并生成最终的输出结果,这一过程的分布式实现使得它特别适用于处理海量数据。
3、朴素贝叶斯分类
朴素贝叶斯分类是基于贝叶斯定理的一种简单概率分类器,假设特征之间相互独立,它通过计算先验概率和似然概率来估计后验概率,从而实现对新样本的分类,该分类器易于实现,对于大规模数据集而言,尤其需要高效的计算模型如MapReduce来支持其训练和应用过程。
4、结合MapReduce实现朴素贝叶斯分类
在Hadoop平台上,利用MapReduce模型实现朴素贝叶斯分类涉及多步MapReduce作业,第一个作业通常用于数据预处理,包括数据清洗和特征提取,随后的作业可能专注于计算词频、计算先验和似然概率等,每个作业的输出作为下一个作业的输入,最终实现从大量训练数据中学习和分类。
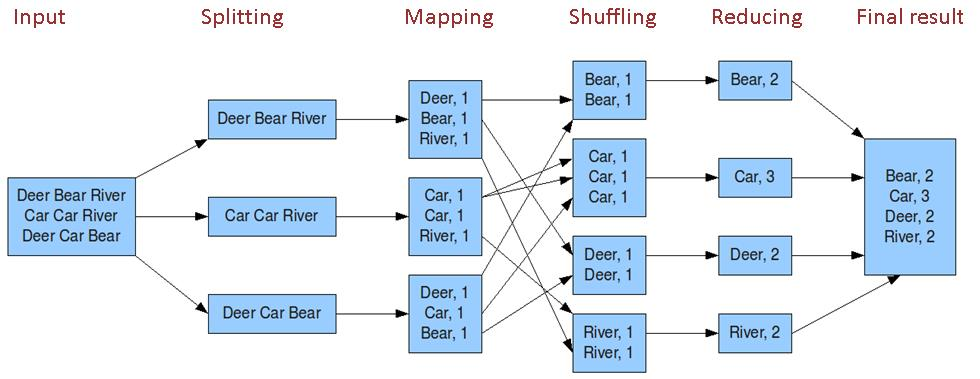
5、案例分析
以文档分类为例,使用Hadoop平台处理数GB的文本数据,在此过程中,首先通过Map函数对文档进行分词并标记,然后通过Reduce函数统计词频和文档频率,这些统计结果用于计算每个词的概率,最后根据朴素贝叶斯公式对新文档进行分类。
6、相关问题与解答
Q1: MapReduce如何处理朴素贝叶斯分类中的数据稀疏问题?
A1: 数据稀疏是机器学习中常见的问题,特别是在处理大规模文本数据时,在使用MapReduce实现朴素贝叶斯分类时,可以通过平滑技术(如拉普拉斯平滑)来调整概率估计,减少未出现特征对模型的影响,MapReduce允许并行处理,可以有效地整合更多数据源,增加模型的泛化能力。
Q2: 如何优化MapReduce作业以提高朴素贝叶斯分类的性能?
A2: 优化MapReduce作业的一种方法是合理设置数据倾斜处理,比如采用随机化或哈希技术分散Key值,避免单个Reducer过载,可以考虑在数据预处理阶段进行更精细的特征选择,减少不必要的计算,适当增加Reducer的数量也可以提高处理速度,但需要根据实际硬件资源进行调整。
MapReduce模型为朴素贝叶斯分类提供了一种高效、可扩展的实现方式,特别适合于处理大规模数据集,通过优化MapReduce作业配置和算法细节,可以进一步提升分类性能和准确度,使其在实际应用中展现出更大的潜力。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591856.html
 微信扫一扫
微信扫一扫