

在当今大数据时代,如何高效地将海量数据加载到HBase中是许多企业和开发者面临的挑战,使用MapReduce配合多个Mapper来提升HBase BulkLoad工具的批量加载效率是一种有效的解决方案,下面详细探讨这一方法的实施步骤、优势以及注意事项。


一、理解BulkLoad和MapReduce的基本概念
1、BulkLoad的定义和作用
定义:BulkLoad是HBase提供的一种数据批量导入方式。
作用:通过直接生成符合HBase内部数据格式的文件,即HFile,并将其加载到集群中,从而提高数据的写入效率并降低对Region Server节点的压力。
2、MapReduce的角色
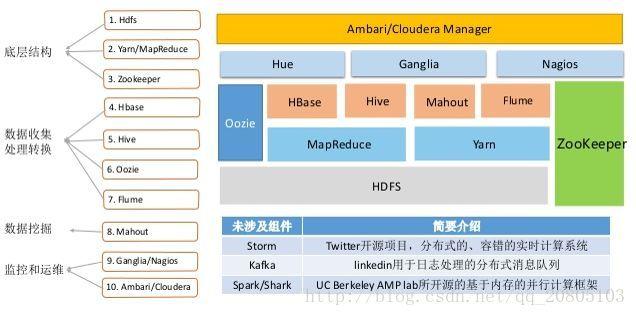
数据处理:MapReduce是一个编程模型,用于大规模数据集的并行处理。
与BulkLoad的结合:通过MapReduce作业直接生成HBase的底层存储文件HFile,再利用BulkLoad将这些文件导入到HBase表中。
实施步骤和操作指南
1、环境准备
MRS集群创建:基于云服务平台(如华为云)创建MapReduce服务集群,为后续操作提供计算资源。
HBase表的创建和检查:使用HBase的Admin API进行表的创建或确认其存在,预备好接收数据。
2、数据的准备和格式化
数据采集:收集需要导入HBase的数据,可能存储于HDFS或其他文件系统中。
数据格式化:通过MapReduce作业处理原始数据,将其转化为HFile格式,以便后续能被HBase直接使用。
3、执行BulkLoad操作
HFile的生成:运行MapReduce任务,输出HFile格式的文件至HDFS的指定目录中。
文件的加载:调用HBase的BulkLoad功能,将之前生成的HFile文件加载到指定的HBase表中。
优势和效益
1、提高效率
节约资源:相比直接使用HBase API,使用BulkLoad能更有效地利用CPU和网络资源,减少资源的浪费。
加速数据加载:特别在首次大量数据加载时,BulkLoad能显著提高写入效率,缩短数据准备到可用的时间窗。
2、减轻压力
降低对服务器的影响:通过批量加载减轻了对Region Server节点的写入压力,避免了因数据写入导致的服务器负载过重问题。
注意事项
1、数据一致性和错误处理
检查数据一致性:在数据转换和加载过程中要确保数据的一致性,防止数据丢失或错误。
错误处理机制:实施过程中要设定合理的错误处理机制,对于可能出现的问题如网络故障、数据格式错误等要有预案。
2、性能优化
硬件资源配置:根据数据量和处理需求合理配置硬件资源,如内存大小、CPU核心数等,以保证处理效率。
参数调优:对Hadoop和HBase的配置参数进行优化,如调整Block大小、缓存设置等,进一步提升性能。
相关问题与解答
Q1: 使用BulkLoad是否适合所有类型的数据导入?
A1: 不是,BulkLoad主要适用于大规模数据的初次导入,对于持续的小批量数据更新,频繁使用BulkLoad可能不会获得预期的效率提升,因为每次操作都需要生成新的HFile和调用BulkLoad过程。
Q2: 如何确保在MapReduce过程中数据的安全性和完整性?
A2: 可以通过在MapReduce作业中加入数据校验机制,比如CRC校验,来确保数据的完整性,确保HDFS和其他涉及到的系统具备适当的安全措施,如数据加密和访问控制,以保障数据的安全性。
通过上述分析可见,利用MapReduce与多个Mapper提升HBase BulkLoad工具的批量加载效率是一个高效且实用的方案,它不仅能够显著提高数据处理的速度,还能有效减轻服务器的负担,每个环节的优化和准备工作都是保证最终成功实施的关键,希望以上内容能够帮助到需要进行大规模数据导入的开发者和管理员,确保他们的数据导入工作既高效又顺利。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591884.html
 微信扫一扫
微信扫一扫