

mapreduce框架适合做传感框架
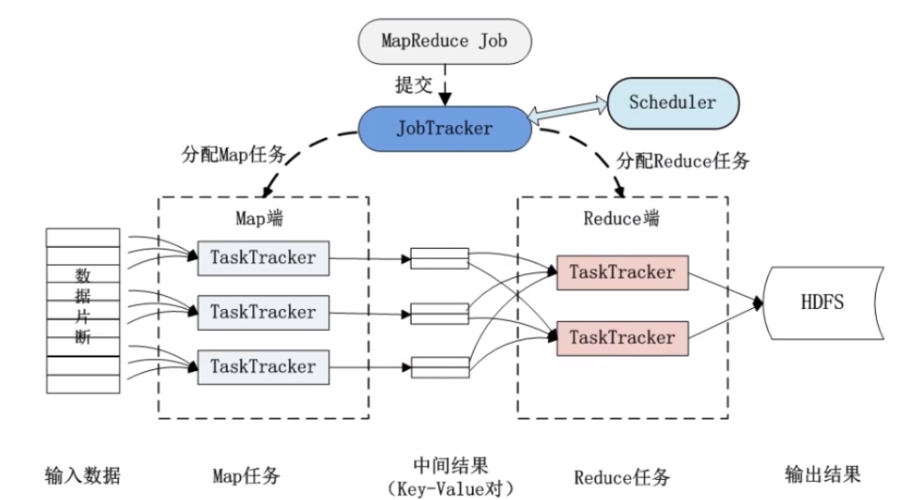
mapreduce是一种编程模型,用于处理和生成大数据集,它通过将任务分解成两个阶段——映射(map)和归约(reduce)——来简化数据处理过程,在传感器网络中,由于数据量巨大并且分散在多个节点上,使用mapreduce框架可以有效地处理这些数据。
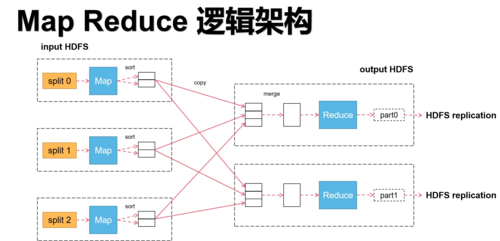
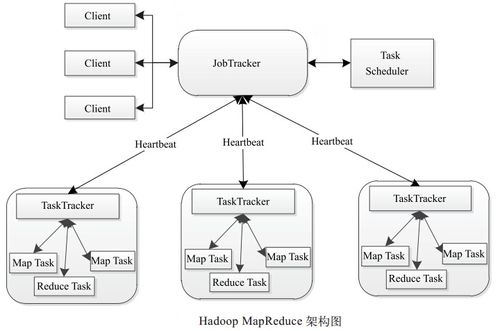
mapreduce的工作原理
map阶段:每个map任务处理输入数据的一个子集,并产生一组中间键值对。
shuffle阶段:系统自动排序并把所有map任务产生的具有相同键的值集合在一起。
reduce阶段:reduce任务遍历所有排序后的键值对,并为每个键执行用户定义的归约函数。
为什么mapreduce适合传感框架
1、并行处理能力:mapreduce允许在多个计算节点上同时处理数据,这对于大规模传感器网络而言至关重要。
2、容错性:框架能够处理节点故障,确保数据处理不会因为单个节点的问题而中断。
3、扩展性:随着传感器数量的增加,mapreduce框架可以轻易地扩展以处理更多的数据。
4、数据局部性优化:在map阶段,可以在数据所在的节点上进行计算,减少数据传输成本。
应用实例
假设有一个温度监测系统,包含数百个分布在不同地理位置的温度传感器,每个传感器定期记录温度数据,使用mapreduce框架,可以按以下步骤处理这些数据:
map阶段:每个传感器作为一个map任务,将采集到的温度数据转换为键值对(时间戳,温度)。
shuffle阶段:系统将所有map任务输出的键值对按照时间戳排序。
reduce阶段:reduce任务汇总相同时间戳的温度数据,可能还会计算平均值或其他统计信息。
相关问题与解答
q1: mapreduce框架如何处理实时数据流?
a1: mapreduce本身是为批处理设计的,对于实时数据流处理并不是最优选择,可以通过结合其他技术如apache storm或apache kafka来实现实时数据的预处理,然后再用mapreduce进行分析。
q2: mapreduce在传感器网络中面临的最大挑战是什么?
a2: 最大的挑战之一是网络带宽和延迟,传感器网络通常涉及大量的数据传输,如果网络带宽有限或不稳定,可能会严重影响mapreduce作业的性能和完成时间,传感器节点的能量限制也是一个重要考虑因素,因为频繁的数据传输和处理会消耗大量能量。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591928.html
 微信扫一扫
微信扫一扫 