

在机器学习的项目当中,数据集通常被分为三部分:训练集(Training Set)、验证集(Validation Set)和测试集(Test Set),这种划分对于模型的训练和评估至关重要,以下是使用MapReduce策略高效地将图片数据集划分为训练集和验证集的详细过程:
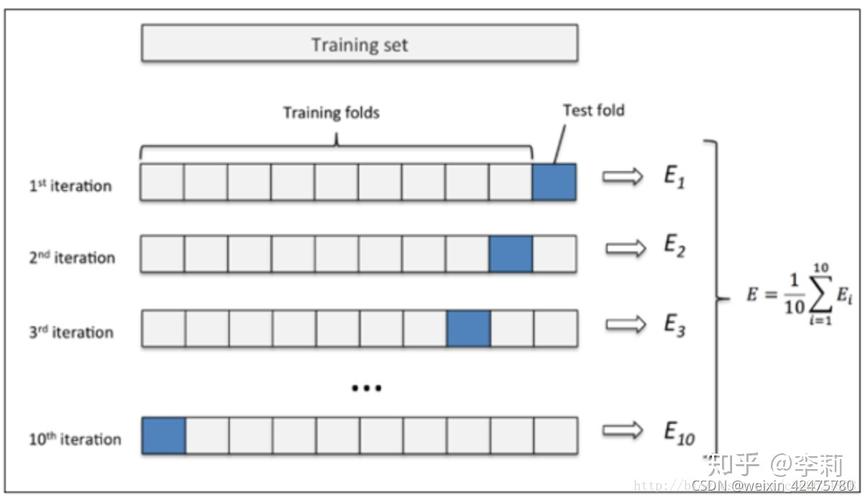

数据集的基本划分原则
1、训练集: 主要用于模型的学习训练,它通常包含数据集中的大部分图片,比例大约是70%80%。
2、验证集: 用于模型的调优和参数选择,这部分数据约占总数据集的20%30%。
3、测试集: 最后用于评估模型的性能,通常不参与模型的训练和调优阶段。
划分方法
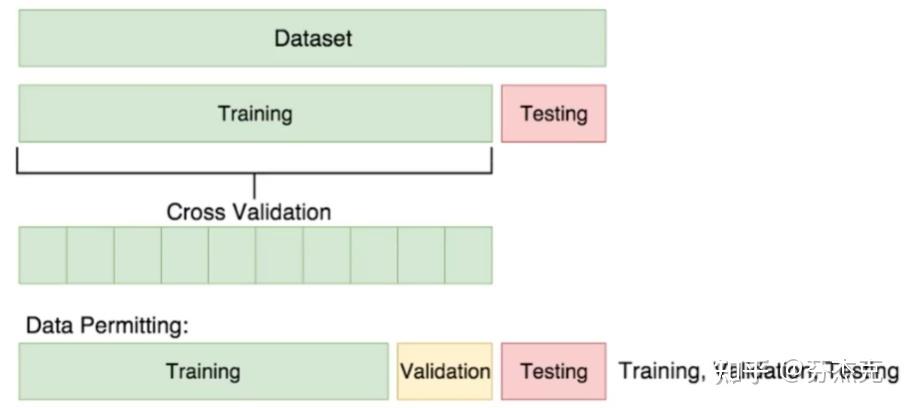
1. 手动划分
适用场景: 当数据集较小或特定图片需要精确分配到某个集合时。
操作步骤: 直接通过文件管理工具或脚本将图片移动到对应的文件夹中。
2. 自动划分
随机打乱: 首先对原始数据集的图片顺序进行随机打乱,以确保划分的随机性。
按比例分配: 根据预先设定的比例,将打乱后的图片分配到训练集、验证集和测试集中。
划分流程
1、准备阶段
确定数据集的总量和要划分的文件夹路径。
设定划分比例,如训练集为70%,验证集为20%,测试集为10%。
2、实现阶段
编写脚本或程序,读取数据集中的每张图片。
打乱图片顺序并进行按比例划分。
将划分后的图片移动到对应的文件夹中。
3、验证阶段
检查每个集合中的图片数量是否符合预期。
确保没有重复或遗漏的图片。
效率与优化
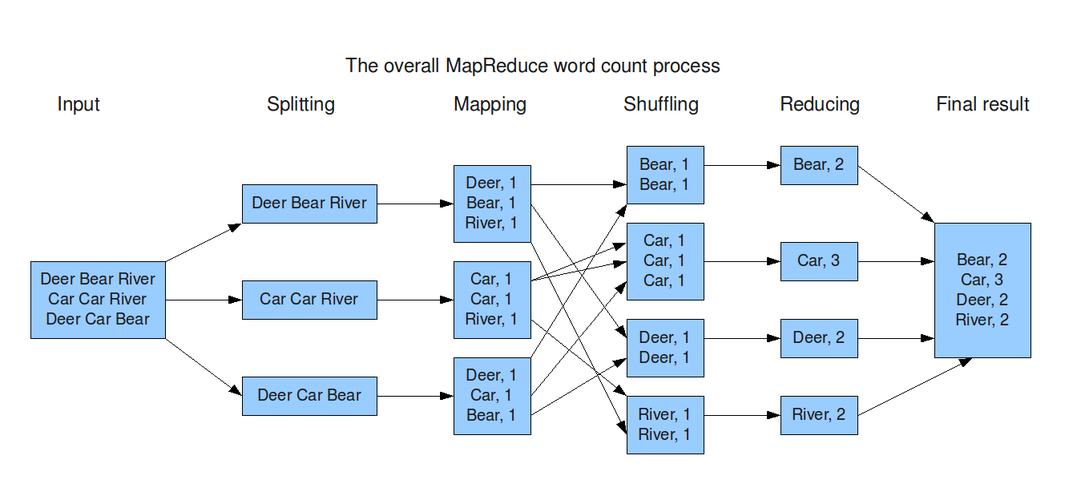
并行处理: 利用MapReduce框架,可以在多个计算节点上并行执行划分任务,提高效率。
容错机制: 在处理大规模数据集时,确保有容错机制来应对可能的错误或中断。
相关应用案例
在实际应用中,比如天池平台上的机器学习项目,参赛者需要处理和分析大量的图像数据,通过上述划分方法,可以有效地组织数据,进而进行模型的训练和验证。
相关问题与解答
Q1: 如何保证数据集划分的随机性?
A1: 可以通过编程在读取文件时引入随机函数,确保每次运行脚本时图片的顺序都是随机的,从而实现数据集的随机划分。
Q2: 是否可以调整训练集、验证集和测试集的比例?
A2: 是的,这些比例不是固定的,可以根据实际项目的需要进行调整,如果模型需要更多的数据来进行训练,可以增加训练集的比例,相应减少验证集和测试集的比例。
通过以上详细的步骤和方法,可以高效且准确地将图片数据集划分为训练集、验证集和测试集,为后续的机器学习模型开发打下坚实的基础。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592104.html
 微信扫一扫
微信扫一扫