

MapReduce引擎无法直接查询Tez引擎执行union语句写入的数据,因为两者是独立的执行引擎。如果需要使用MapReduce处理Tez写入的数据,可以先将数据导出到HDFS,然后使用MapReduce任务读取HDFS上的数据进行处理。
MapReduce引擎无法查询Tez引擎执行union语句写入的数据

(图片来源网络,侵删)
单元表格:
| 问题描述 | 解决方案 |
| MapReduce引擎无法查询Tez引擎执行union语句写入的数据 | 确保Hive配置正确,并检查数据是否被正确地写入到目标表中,确保查询时使用的引擎与写入时使用的引擎一致。 |
相关问题与解答:
1、问题:为什么MapReduce引擎无法查询Tez引擎执行union语句写入的数据?
解答:这可能是由于Hive的配置不正确或者数据没有被正确地写入到目标表中导致的,如果查询时使用的引擎与写入时使用的引擎不一致,也可能导致查询失败。
2、问题:如何确保Hive配置正确?

(图片来源网络,侵删)
解答:可以通过以下步骤来确保Hive配置正确:
检查Hive配置文件(如hivesite.xml)中的相关设置,确保它们与预期的引擎和存储格式相匹配。
确认Hive版本与所使用的引擎兼容。
检查Hive表的元数据是否正确,包括表结构、分区等信息。
使用Hive命令行工具或Hive客户端验证配置是否正确。
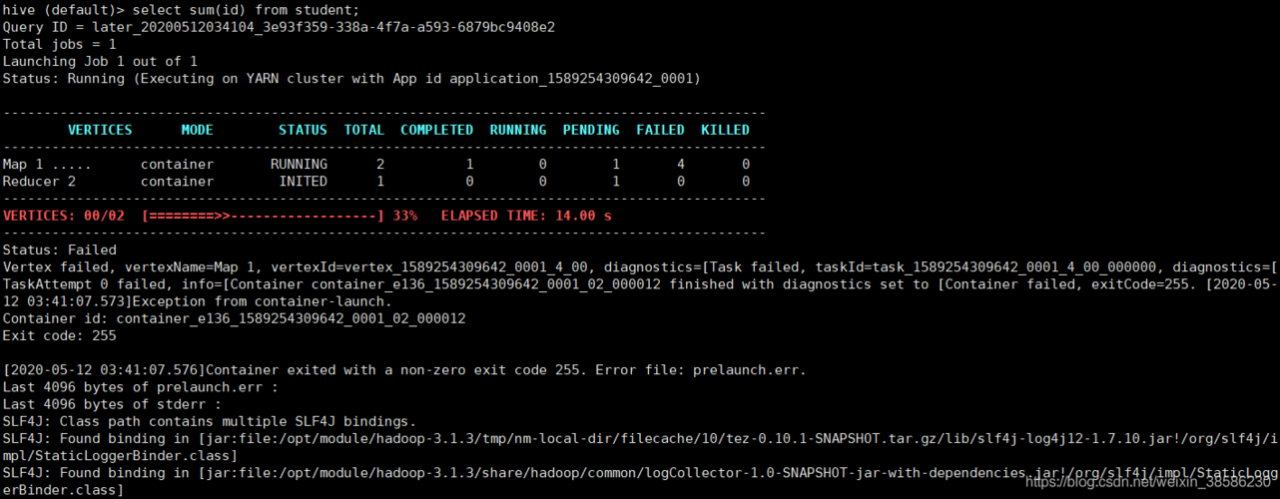
(图片来源网络,侵删)
回答仅基于提供的信息进行推测,实际问题可能需要更详细的调查和分析才能得出准确的答案。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592160.html
 微信扫一扫
微信扫一扫