

MapReduce函数原理图
全面解析数据处理的核心概念与执行流程
【导语】
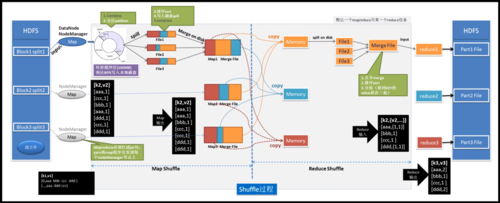
MapReduce,作为一种编程模型,是处理和生成大数据集的关键技术,此技术最初由谷歌提出,主要用于大规模集群上的简化数据处理,具体到MapReduce的工作原理,其可以分为Map(映射)和Reduce(归约)两个主要阶段,本文将深入探讨MapReduce的工作原理,并解答与之相关的常见问题。
Map阶段详解
数据分片:输入数据集首先被分割成多个块,每个块由一个Mapper处理。
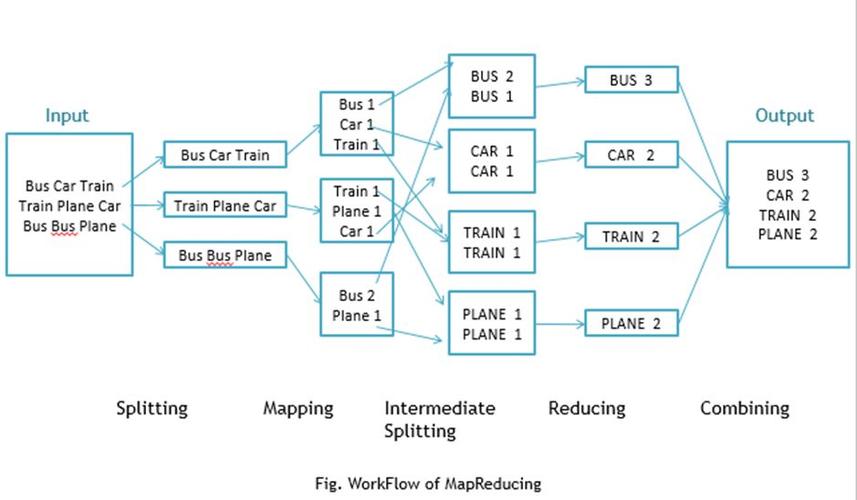
映射函数应用:每个Mapper读取数据块,并将数据元素转换成键值对。
中间键值对生成:映射函数输出形成中间键值对,为Shuffle阶段做准备。
Shuffle阶段:中间结果根据键进行分组并分配给对应的Reducer。
Reduce阶段详解
键值整合:Reducer获取一组具有相同键的值,通过reduce函数合并。
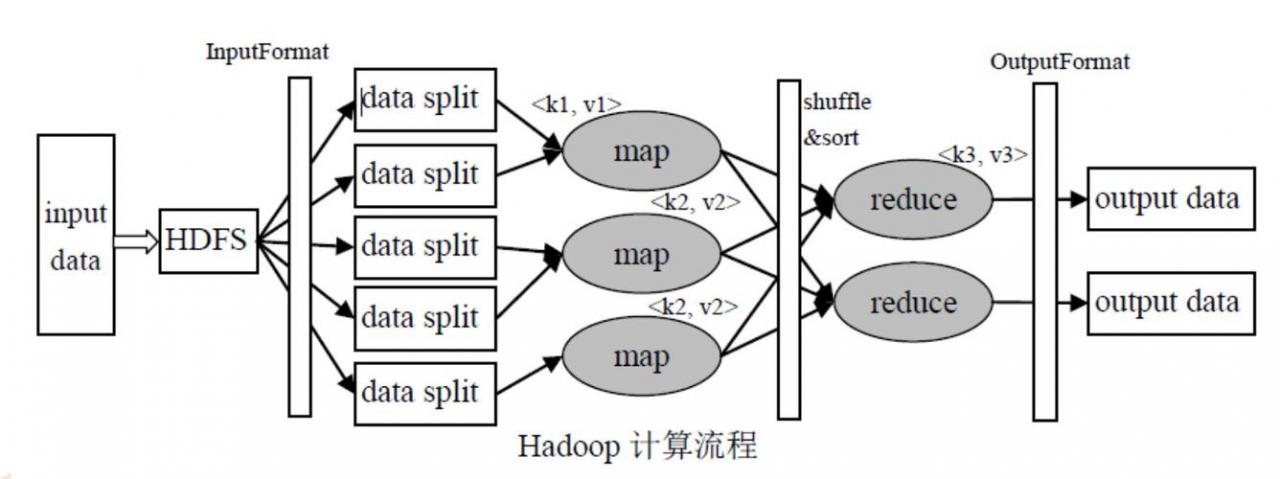
最终结果输出:产生最终结果,通常规模更小,可直接用于后续处理或存储。
MapReduce框架
分布式计算框架:MapReduce是一个分布式计算框架,用于开发基于Hadoop的数据分析应用。
编程模型与运行时环境:提供简单的编程接口,并自动处理节点间通信、数据切分等复杂问题。
特性与设计思想
易于编程:用户仅需实现几个简单函数即可创建分布式程序。
高容错性:系统能自动处理节点失效等问题,保证计算任务的顺利完成。
【相关问题与解答】
Q1: MapReduce适用于哪些场景?
A1: 特别适合于需要处理大量非结构化或半结构化数据的场景,如日志分析、大数据处理、互联网索引等。
Q2: MapReduce在数据处理中的主要优势是什么?
A2: 主要优势包括程序的易编写性、高度的可扩展性和强大的容错能力,使得它非常适合处理PB级数据。
归纳与展望
MapReduce作为大数据分析的重要工具,通过其独特的Map和Reduce操作,极大地简化了数据处理的复杂性,尽管面临新型数据处理框架的竞争,MapReduce仍然是学习和理解分布式系统的基础,随着技术的发展,MapReduce可能会在效率和功能上有所改进,继续服务于更大规模的数据处理需求。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592228.html
 微信扫一扫
微信扫一扫 