

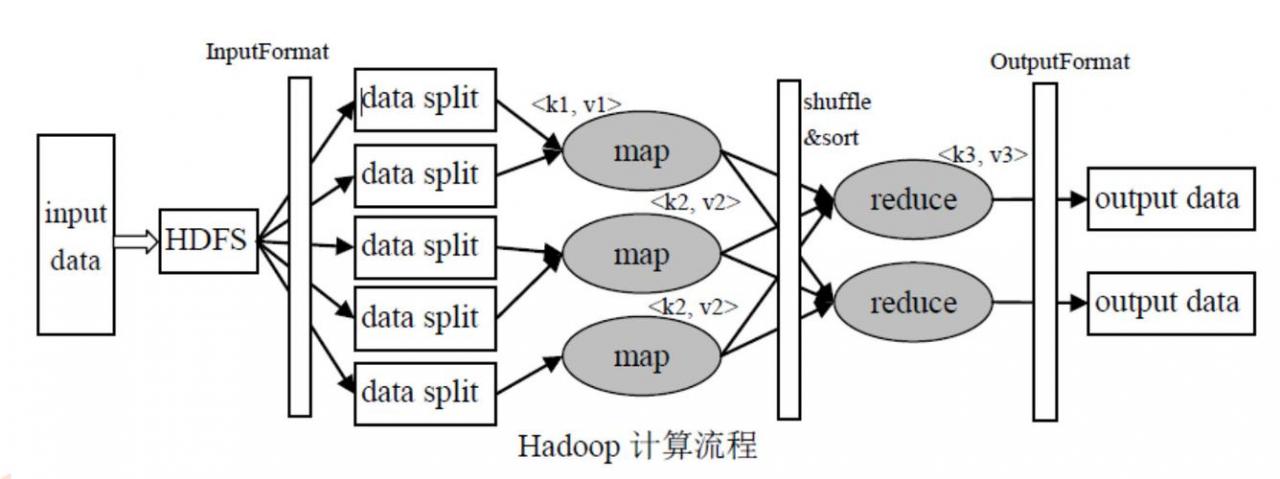
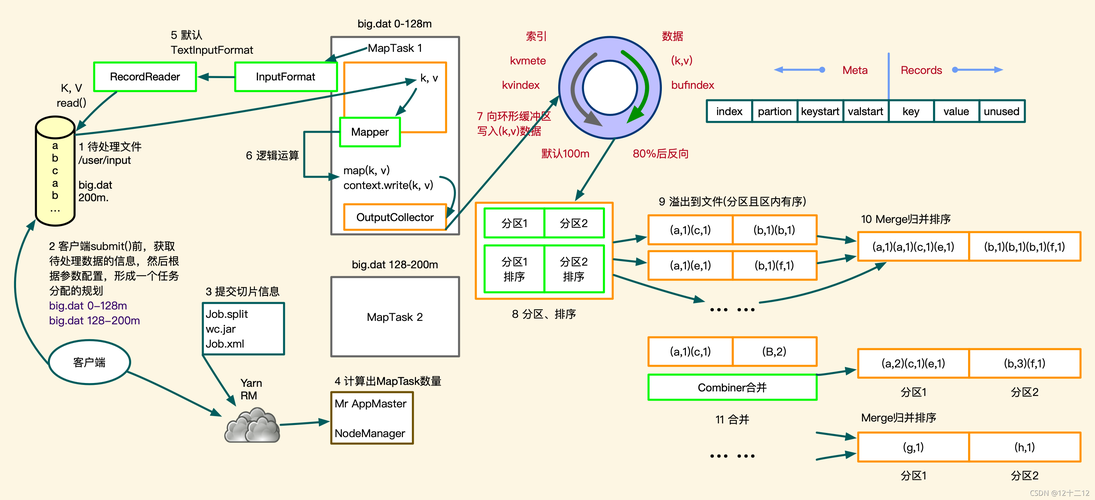
MapReduce 中的列表处理(list_list)
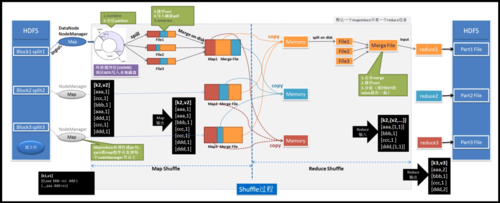

MapReduce 是一种编程模型,用于处理和生成大数据集,它包括两个主要阶段:映射(Map)和归约(Reduce),在处理列表数据时,MapReduce 可以高效地对列表中的元素进行操作和聚合。
映射阶段(Map)
在映射阶段,输入数据被分成多个小数据块,每个数据块由一个映射任务处理,对于列表数据处理,映射函数会将列表中的每个元素转换为键值对。
示例
假设我们有一个包含多个列表的列表,如下所示:
input_list = [[1, 2, 3], [4, 5], [6, 7, 8, 9]]
映射函数可能会输出以下键值对:
[(0, 1), (0, 2), (0, 3), (1, 4), (1, 5), (2, 6), (2, 7), (2, 8), (2, 9)]
这里,每个元素的索引作为键,元素本身作为值。
归约阶段(Reduce)
归约阶段接收映射阶段输出的所有键值对,并根据键将其分组,归约函数会对每个组应用一个汇总操作,例如计算总和、平均值或其他统计信息。
示例
继续上面的例子,归约阶段可能会接收以下分组:
[
(0, [1, 2, 3]),
(1, [4, 5]),
(2, [6, 7, 8, 9])
]
如果归约函数是计算列表长度,那么输出将是:
[(0, 3), (1, 2), (2, 4)]
相关问题与解答
Q1: 如果输入列表非常大,如何优化 MapReduce 作业?
A1: 如果输入列表非常大,可以考虑以下优化策略:
分片(Sharding): 将大列表分成多个小列表,每个小列表由不同的映射任务处理。
并行处理: 在不同的机器或集群上运行多个映射和归约任务,以利用并行计算能力。
内存管理: 使用有效的内存管理技术,如压缩和内存缓存,以减少数据传输和存储成本。
优化算法: 根据具体问题优化映射和归约函数,减少不必要的计算和数据传输。
Q2: MapReduce 是否适用于所有类型的列表处理任务?
A2: MapReduce 非常适合于数据密集型和计算密集型的列表处理任务,特别是那些可以并行化的任务,对于需要频繁迭代和实时更新的任务,MapReduce 可能不是最佳选择,因为它是为批量处理设计的,在这些情况下,其他模型,如流处理或实时计算框架,可能更合适。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592335.html
 微信扫一扫
微信扫一扫