

在MapReduce框架中,数据切分是实现分布式计算的关键步骤之一,数据集的切分方法直接影响到MapReduce作业的性能和效率,本文将详细探讨如何在MapReduce中进行数据切分,包括切分的方法、考虑因素以及相关设置。

数据切分的基本概念
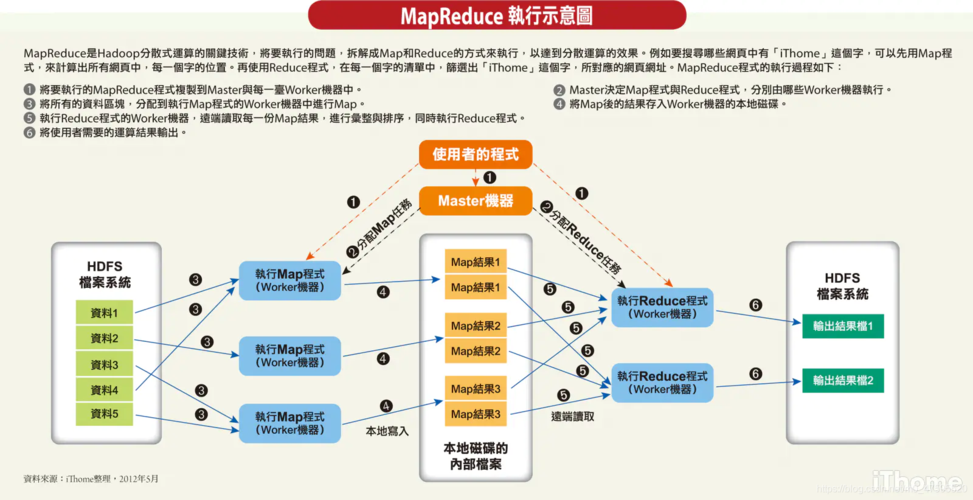
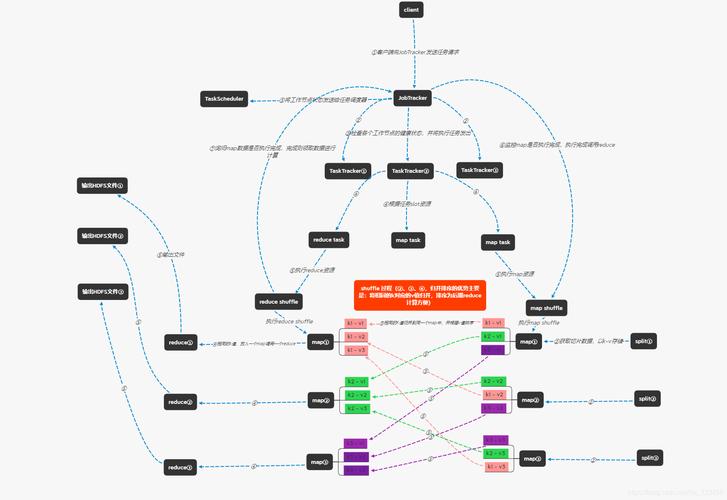
在MapReduce模型中,数据切分是将输入数据集分割成多个较小的片段,每个片段由一个map任务处理,合理的数据切分可以确保工作负载均匀分配,从而提高整体的处理速度和效率。
数据切分的关键步骤
1、获取输入路径:
需要从配置的参数mapred.input.dir中获取MapReduce任务的输入路径,这些路径指向HDFS中的文件或目录。
2、计算文件总大小:
计算所有输入路径下的文件总大小totalSize,这一信息对于后续确定如何切分文件至关重要。
3、确定Map任务个数:
根据总数据量和单个Map任务的理想处理能力,系统会自动设定Map任务的数量,通常情况下,Map任务的数量与数据的总大小和HDFS的块大小(block size)有关。
4、计算目标文件大小:
每个Map任务处理的数据量通常与HDFS上的一个块大小相等,这样设计是为了减少网络传输开销并提高效率。
5、设置Split Size:
根据前面的计算结果设定每个split的大小,即每个Map任务将要处理的数据量。
6、进行文件分割:
实际执行数据切分操作,按照计算出的split size来分割文件。
7、存储分割信息:
最后将分割信息保存,以供MapReduce作业执行时使用。
数据切分的高级策略
1、自定义分区:
在某些情况下,可能需要根据数据的特性(如关键字、范围等)自定义分区逻辑,以确保相关的数据被同一个Map任务处理。
2、使用MultipleOutputs:
对于需要输出到不同文件的数据,可以使用Hadoop的MultipleOutputs类,以便根据需求对输出数据进行重命名和分类。
优化数据切分的考虑因素
1、数据本地化:
尽量让数据在数据所在的节点上进行处理,以减少网络传输的开销。
2、平衡负载:
确保每个Map任务分配到的数据量大致相等,避免某些节点过载而影响整体性能。
相关问题与解答
Q1: MapReduce中是否可以动态改变Map和Reduce的数量?
A1: 是的,可以通过代码或配置文件在作业提交前动态设置Map和Reduce的数量,通过调用job.setNumReduceTasks(x)可以设置Reduce任务的数量,Map任务的数量通常由数据切分和输入split的大小决定。
Q2: 数据切分是否只适用于文本数据?
A2: 数据切分不仅限于文本数据,虽然在处理文本数据时,按行切分是一种常见的做法,但在处理二进制数据或其他类型数据时,也可以根据实际需求实施不同的切分策略,关键是要分析数据的特性和处理需求,选择最适合的切分方法。
通过上述详细的讨论,可以看出在MapReduce中进行有效的数据切分是提高数据处理效率的关键,适当的切分策略不仅能够优化资源的使用,还能显著提升作业执行的速度,希望本文能为理解和应用MapReduce数据切分提供实用的指导和帮助。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592358.html
 微信扫一扫
微信扫一扫