

详解RabbitMQ客户端连接报错原因

在集成和使用RabbitMQ过程中,客户端连接报错是一个常见的问题,了解和解决这些问题对于保障消息队列服务的稳定运行至关重要,以下是对RabbitMQ客户端连接报错的详细分析与解决方案。
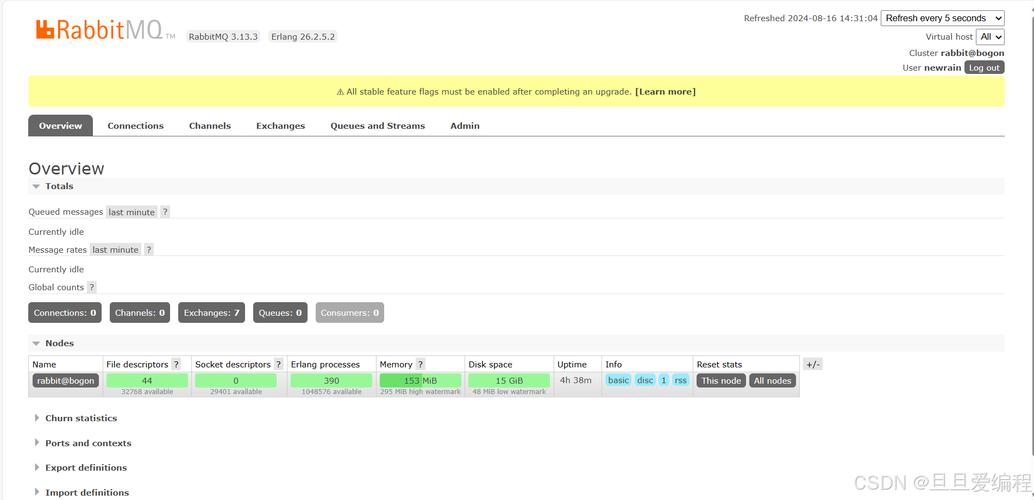
地址和端口配置错误
原因分析
客户端连接RabbitMQ服务器时需指定正确的地址和端口,错误的地址或端口信息会直接导致连接失败。
地址错误:尤其在VPC内访问场景下,若连接地址不正确,将无法找到RabbitMQ服务端。
端口错误:默认情况下,RabbitMQ服务器使用5672端口,若端口号填写错误或服务器配置不同,也会导致连接失败。
解决策略
核对地址:确认RabbitMQ服务器的IP地址或域名是否正确,特别是在分布式环境或云服务环境下。
确认端口:检查RabbitMQ服务端口是否为预期值,通常为5672,如有更改则需要同步更新客户端配置。
认证失败
原因分析
RabbitMQ要求正确的用户名和密码进行连接认证,错误的凭证会导致认证失败,进而引起连接错误。
用户名密码错误:客户端使用的用户名和密码若与服务器配置不一致,将会被服务器拒绝连接。
权限问题:即使认证通过,用户权限不足也可能限制执行特定操作。
解决策略
凭证匹配:确保客户端使用的用户名和密码与服务器上的配置完全一致。
用户权限:检查用户在RabbitMQ服务器上的权限配置,确保其具有足够的权限执行需要的操作。
网络问题
原因分析
网络连接是RabbitMQ客户端与服务器交互的基础,任何网络层面的问题都可能导致连接失败。
网络延迟与带宽:高延迟或低带宽的网络环境可能导致连接建立缓慢甚至超时。
连接稳定性:不稳定的网络连接可能导致间歇性的连接断开。
解决策略
网络优化:优化网络路径,增加带宽,降低延迟。
稳定性检查:检查网络连接的稳定性,避免通过不稳定的无线网络或公共网络进行关键数据传输。
服务器性能问题
原因分析
RabbitMQ服务器的性能直接影响其处理连接请求的能力,性能不足可能导致新连接请求被拒绝或超时。
资源饱和:服务器CPU、内存或磁盘资源不足,会影响处理效率。
请求积压:高并发请求下,服务器处理能力达到上限,可能暂时无法接受新的连接请求。
解决策略
资源监控与扩展:持续监控服务器资源使用情况,必要时进行硬件升级或扩展。
流量控制:合理设计消费者和生产者的数量和速率,避免突发大流量影响服务器稳定性。
客户端配置问题
原因分析
客户端的配置错误或不当操作也是导致连接失败的常见原因之一。
错误配置:客户端配置文件中的错误或遗漏,如错误的交换器、队列声明等。
代码问题:客户端应用程序代码存在逻辑错误或兼容性问题。
解决策略
配置审核:仔细检查客户端的配置文件,确保所有设置项正确无误。
代码调试:对客户端应用程序代码进行调试,修正可能存在的逻辑或兼容性问题。
RabbitMQ客户端连接报错可能由多种因素引起,包括配置错误、认证失败、网络问题、服务器性能问题以及客户端配置问题等,解决这些问题需要从多个角度出发,综合考虑并采取相应措施,理解和识别这些常见问题及其解决策略,有助于快速定位并解决RabbitMQ在实际使用中遇到的连接问题,保证消息队列服务的高效稳定运行。
相关问题与解答
问题1:如何解决RabbitMQ客户端连接超时的问题?
回答
解决连接超时问题,首先应确认RabbitMQ服务器已正确启动且地址端口配置无误,检查网络连接是否存在延迟过高或带宽不足的问题,必要时进行网络优化,考虑是否存在服务器性能瓶颈,通过监控资源使用情况并进行适当扩展来解决问题。
问题2:如果RabbitMQ客户端连接频繁断开怎么办?
回答
面对频繁的连接断开问题,应从网络稳定性入手,确保客户端与服务器之间的网络连接稳定可靠,检查RabbitMQ服务器的日志,寻找可能的性能瓶颈或资源不足问题,审查客户端应用程序代码,确保没有不当的资源管理或连接保持逻辑。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592534.html
 微信扫一扫
微信扫一扫