

MapReduce原理和执行过程


背景、原理与执行流程详解
编辑推荐:本文将深入探讨MapReduce的背景、设计原理及其执行过程,帮助读者全面理解这一大数据处理的核心技术。
背景介绍
MapReduce,作为大数据处理领域的核心计算模型之一,自提出以来便因其高效、可靠的数据处理能力而被广泛应用于各种数据密集型应用中,在Hadoop生态系统中,MapReduce扮演着至关重要的角色,尽管随着技术的发展,新的计算框架不断涌现,MapReduce仍保持着其不可替代的地位。
MapReduce原理
1、概念解析
MapReduce模型主要由两个阶段组成:Map阶段和Reduce阶段,Map负责数据的过滤和排序,而Reduce则负责数据的汇总和归纳。

2、Map与Reduce函数
表1: Map与Reduce函数功能对比
| 函数类型 | 主要功能 |
| Map | 处理数据分片,生成中间键值对 |
| Reduce | 处理中间键值对,按键聚合数据并输出结果 |
3、核心优势
MapReduce的设计允许任务在数千台计算机上并行处理,极大地提高了数据处理的速度和效率,其“稳定存储到稳定存储”的数据流模式确保了数据处理的高可靠性。
MapReduce执行流程
1、数据准备阶段
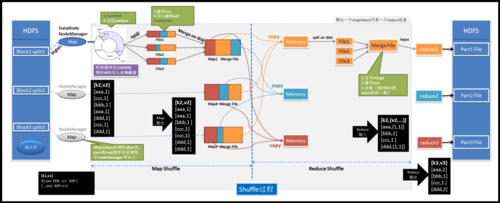
在执行MapReduce作业之前,输入数据源需要经过分片(Splitting)和格式化操作,转换为键值对形式,以便后续处理。
2、Map阶段
Map任务开始执行,每个Map任务处理一个数据分片,通过用户定义的map()函数,将输入的键值对转换为一系列新的中间键值对。
3、Shuffle阶段
Shuffle阶段是连接Map和Reduce的桥梁,它负责对Map输出的键值对进行排序和分组,确保相同键的数据被发送到同一个Reduce任务。
4、Reduce阶段
Reduce任务接收来自Shuffle的中间数据,通过用户定义的reduce()函数进行处理,最终输出结果数据。
执行过程特点
MapReduce的设计确保了大规模数据处理的高效性,同时也简化了编程复杂度,通过自动的并行化和错误恢复机制,MapReduce使得开发者能够轻松编写出能处理海量数据集的程序。
相关案例与应用
以WordCount为例,这是MapReduce编程的典型入门案例,通过统计文本数据中各单词的出现次数,展示了MapReduce模型处理数据的基本流程。
相关问题与解答
Q1: MapReduce适合实时数据处理吗?
A1: 不适合,由于MapReduce的设计是为了处理批量数据,它的数据处理延迟较高,不适合对实时性要求高的场景,对于实时数据处理,可以考虑使用如Apache Spark等其他框架。
Q2: MapReduce在当前大数据技术生态中的地位如何?
A2: 尽管出现了许多新的计算框架,但MapReduce仍然是Hadoop生态系统中不可或缺的一部分,尤其是在需要处理大规模非结构化数据时,对于特定的应用场景和需求,可能会优先选择其他更高效的框架。
MapReduce作为一种强大的分布式数据处理模型,在处理大规模数据方面展现出了巨大的价值,尽管面临新兴技术的挑战,但其基本原理和应用仍然值得我们深入学习和掌握,随着数据量的不断增长,理解和运用好MapReduce的原理与执行过程,将为处理复杂数据问题提供坚实的基础。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/592542.html
 微信扫一扫
微信扫一扫